for range 的实现
下面这段代码会永无止境的循环吗 ?
package main
import (
"fmt"
)
func main() {
sl := []int{1,2,3,4}
for _, v := range sl{
sl = append(sl, v)
}
fmt.Println(sl)
}
要验证它很简单,运行一下即可得到结果,最后的结果是
[1 2 3 4 1 2 3 4]
要理解为什么会有这样的结果不难,首先我们需要清楚一点 go 语言中的赋值语句都是赋值,那么就意味着
- 如果赋值的是一个指针, 那么拷贝的是指针指向对象的地址(就是一个数值, 至于这个数值有多大, 具体要看运行的平台)也就是指针的值
- 如果赋值的是一个对象, 那么就会拷贝这个对象
然后,我们再来看一下,当 for range 遇到不同的迭代对象时,编译器是如何展开代码的
数组
range_temp := range
len_temp := len(range)
for index_temp = 0; index_temp < len_temp; index_temp++ {
value_temp = range_temp[index_temp]
index = index_temp
value = value_temp
original body
}
slice 切片
for_temp := range
len_temp := len(for_temp)
for index_temp = 0; index_temp < len_temp; index_temp++ {
value_temp = for_temp[index_temp]
index = index_temp
value = value_temp
original body
}
map
// Lower a for range over a map.
// The loop we generate:
var hiter map_iteration_struct
for mapiterinit(type, range, &hiter); hiter.key != nil; mapiternext(&hiter) {
index_temp = *hiter.key
value_temp = *hiter.val
index = index_temp
value = value_temp
original body
}
注:
- 在
range循环里对maps做添加或删除元素的操作是安全的。 - 如果在循环中对
maps添加了一个元素,那么这个元素并不一定会出现在后续的迭代中。
为什么在后续的迭代中不一定能遍历到当前添加的元素 ?因为哈希表内部数组里的元素并不是以特定顺序存放。最后一个添加的元素有可能经过被放到了内部数组里的第一个索引位
channel
// Lower a for range over a channel.
// The loop we generate:
for {
index_temp, ok_temp = <-range
if !ok_temp {
break
}
index = index_temp
original body
}
string
// Lower a for range over a string.
// The loop we generate:
len_temp := len(range)
var next_index_temp int
for index_temp = 0; index_temp < len_temp; index_temp = next_index_temp {
value_temp = rune(range[index_temp])
if value_temp < utf8.RuneSelf {
next_index_temp = index_temp + 1
} else {
value_temp, next_index_temp = decoderune(range, index_temp)
}
index = index_temp
value = value_temp
original body
}
上面虽然分别列举了 5 种类型,但是万变不离其宗,其核心逻辑都是在 for 循环开始前,获取对象的长度,然后在 for 循环內部迭代。 因此,在进入 for 循环前,就决定了迭代几次结束。
小测验
func main() {
var a = [5]int{1, 2, 3, 4, 5}
var r [5]int
for i, v := range a {
if i == 0 {
a[1] = 12
a[2] = 13
}
r[i] = v
}
fmt.Println("r = ", r)
fmt.Println("a = ", a)
}
func main() {
var a = []int{1, 2, 3, 4, 5}
var r = make([]int,5)
for i, v := range a {
if i == 0 {
a[1] = 12
a[2] = 13
}
r[i] = v
}
fmt.Println("r = ", r)
fmt.Println("a = ", a)
}
答案:
第一个输出
r = [1,2,3,4,5]
a = [1,12,13,4,5]
第二个输出
r = [1,12,13,4,5]
a = [1,12,13,4,5]
造成这个结果的主要是两个原因
- 数组 和 slice 的区别,数组赋值是直接 copy,slice 赋值是 copy 指针,len 和 cap。
- 回顾 for range 的实现,在一开头都做了一次赋值
range_temp := range。
因此,第一个例子中 r[i] = v 都是在各自的内存上操作,value_temp = for_temp[index_temp]来自copy 的副本。而第二个例子的 for 循环结构体中 v 的取值来自value_temp = for_temp[index_temp],与原 slice 是同一片内存。
参考资料 2 中给了一些写代码的最佳实践建议:
- 尽量用 index 来访问 for range 中真实的元素 slice[index]。
- go func() 最好通过函数参数方式传递循环中的变量
- 循环变量在每一次迭代中都被赋值并会复用,不是每次都重新声明,地址一样。所以需要区分的时候需要重新每次重新声明临时变量
- 可以在迭代过程中移除一个 map 里的元素或者向 map 里添加元素,添加的元素并不一定会在后续迭代中被遍历到。所以最好不要在 range 迭代中修改 map,容易造成不确定性。
- 遍历对象是引用类型时要注意副本其实依赖于源对象,合理使用。
- 数组和切片因为自身数据结构的不同,range 迭代时表现也不一样,可以根据实际场景进行合理使用。
Slice
关于 Go Slice 的内部结构,网上有很多介绍,总的说来就是下面这张图。
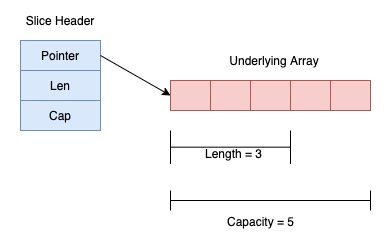
本文关注的是在对 slice 进行截取和 append 时的坑。
首先来分别看下面两段代码,想想为什么他们的结果不一样 ?
func main() {
nums := []int{1, 2, 3, 4, 5, 6}
k := 2
res := append(nums[:k], nums[k+1:]...)
}
// nums = [1 2 4 5 6 6], len = 6, cap = 6
// res = [1 2 4 5 6], len = 5, cap = 6
func main() {
nums := []int{1, 2, 3, 4, 5, 6}
k := 2
res := append(nums[:k:k], nums[k+1:]...)
}
// nums = [1 2 3 4 5 6], len = 6, cap = 6
// res = [1 2 4 5 6], len = 5, cap = 6
看出区别了吗? 区别仅仅在与截取时使用了 nums[:k:k]指定了 cap。
这个坑什么时候会遇到呢 ? 一般情况下,我们用 append 的时候都是这样的
nums = append(nums[:k], nums[k+1:]...)
// nums = [1 2 4 5 6], len = 5, cap = 6
即:把 append 的返回值赋值给他自己。一旦我们把 append 的结果复制给新变量了,并且在后续的代码中又不小心用了 nums,那么错误就会发生。
Slice 截取的原理
为什么会发生上面的情况呢?
- slice 截取操作代价很低,new 一个 slice 结构,data 指针指向原来的数组,通过slice结构的len和cap两个字段,决定当前slice能访问哪些元素,数据量到多少时需要扩容。
- 对新的 slice 进行 append,如果 len还没超过cap,就会在data指向的数组后面追加,且该数组和原数组为同一个,因此会修改原数组的值。
- 对新的 slice 进行 append,如果 len 一定达到 cap,就会对新 slice 进行扩容,分配新的内存,把新 slice 的数据 copy 过去,再对新的内存上的数组进行 append。
截取后,Append 前
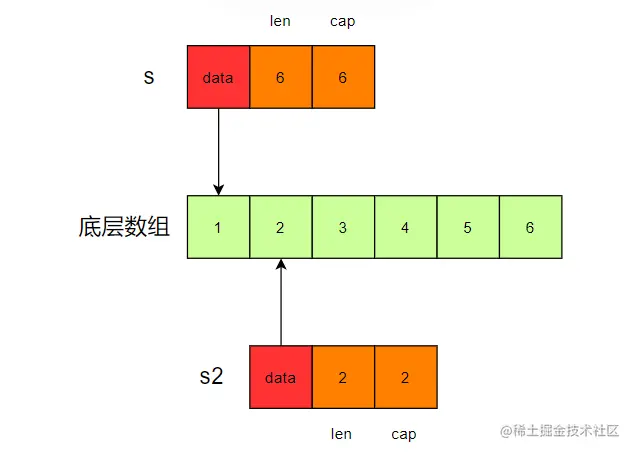
截取后,Append 后
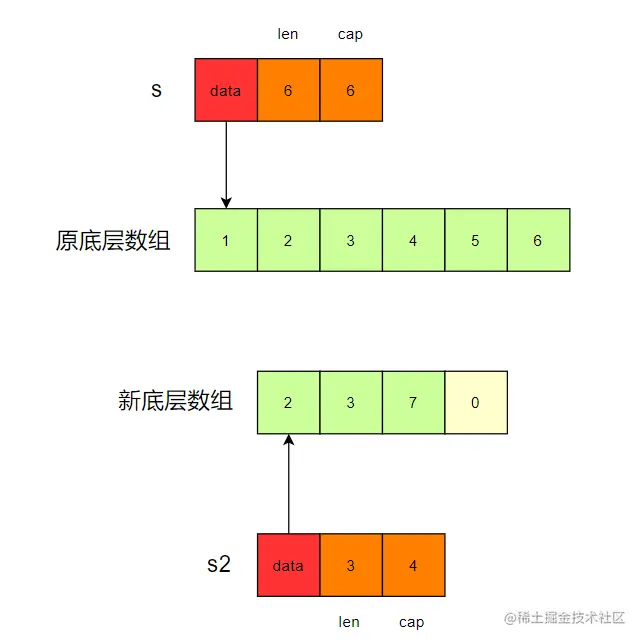
所以,当我们想删除 slice 中的一个元素时,
- 如果还把它赋值给原 slice,这样写没有问题
n = append(n[:k], n[k+1:]...)。 - 当我们想把 append 的结果赋值给新 slice 时,
n = append(n[:k:k], n[k+1:]...)是一个更加保险的方式。