本文是读完 Handling 1 Million Requests per Minute with Go 之后,根据自己的理解,对文中提到的并发模型和实现再梳理一遍。
前言
假设有一个 http server 接收 client 发来的 request,如果用下面的这样的代码,会有什么问题呢?
func payloadHandler(w http.ResponseWriter, r *http.Request) {
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
go payload.UploadToS3() // <----- DON'T DO THIS
}
}
显而易见,有 2 个问题:
- 接收一个 request 就开启一个 goroutine 处理,当 request 数量在短时间内暴增的话,光是 goroutine 的数量都足以让 server 崩溃。
- 每个 goroutine 都会与后端建立 TCP 连接,既耗费三次握手的时间,也会造成后端有大量 TCP 连接
所以,我们的目标是 没有蛀牙
- 可以控制 goroutine 的总数,方法是事先创建好一定数量的 goroutine,加入到一个 Pool 中
- goroutine 启动时与后端建立 TCP 长连接,之后的通信都基于这个连接
根据原文作者给出的方法,整体的架构如下:
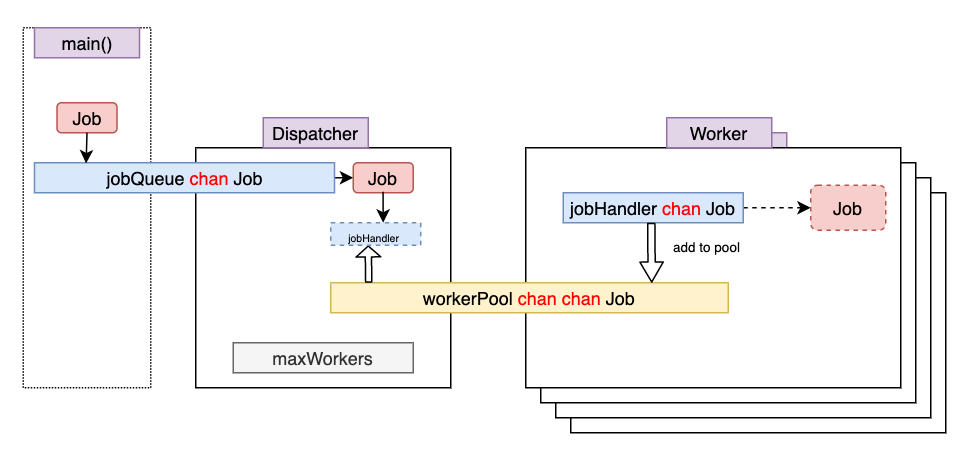
主要有两个数据结构,Dispatcher 和 Woker, Dispatcher 只有一个,Woker 有多个,通过参数控制。
整体上来说,这是一个 生产者-消费者 模型,程序的工作流程如下:
- 程序启动时,Woker 的
jobHandler为空,因此加入到workerPoolchannel 中,Dispatcher 和 Woker 共享一个 workerPool - client 发来 Job,
Dispatcher从workerPool中拿出一个空闲的job,把 Job 塞入其中 - 在
jobHandlerchannel 的另一端,也就是Woker中,马上发现有数据可读,因此读出 Job - 此时,完成了 Job 从进入 server,到分配给一个具体的
Woker处理
原文的代码中 Woker 里面也有名叫 jobQueue,与 Dispatcher 中的 jobQueue 混淆。Dispatcher 的 jobQueue 是来源于 main(),是一个真正的 Queue,我认为 Worker 中的叫 jobHandler 比较合适。
测试
原文中,有人给出了一个具体的实现, 接下来用这个代码做一些简单的测试。
在 server 端开启 1000 个 goroutine
$ ./server --max_workers=1000 --max_queue_size=10000
然后用 Apache bench 工具来做压力测试,其中 n 参数表示一共发多少个 request,c 参数表示同时有多少个并发。
关于 T 参数中的 x-www-form-urlencoded,是最常见的 POST 提交数据的方式。其 HTML payload 类似于下面这样
POST http://www.example.com HTTP/1.1
Content-Type: application/x-www-form-urlencoded;charset=utf-8
title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
Content-Type 被指定为 application/x-www-form-urlencoded 提交的数据按照 key1=val1&key2=val2 的方式进行编码,key 和 val 都进行了 URL 转码。
$ cat data.txt
delay=100ms&name=dummy
$ ab -n 100000 -c 1000 -T 'application/x-www-form-urlencoded' -p data.txt http://192.168.31.31:8080/work
通过执行上面的命令,可以看到在 1000 个并发 request,server 开启 1000 个 goroutine 的情况下,server 端能轻松处理 request,没有出现 timeout 等情况。
对原来的代码稍微做一些修改,每隔两秒打印一下 runtime.NumGoroutines() 的数量。
./goroutine-pool --max_workers=1000 --max_queue_size=10000
runtime.NumGoroutines = 1003
...
runtime.NumGoroutines = 1178
runtime.NumGoroutines = 1232
可以看到,刚刚启动时有 1003 个 goroutine,多出来的 3 个是程序本身的,开启 ab 测试以后最多的时候才 1232 个,可见 go 的效率还是不错的。
更新 2021-02-18
原文和上面的分析都把问题复杂化了,上面的这些编程模式在其他语言中可能适用,但是在 Golang 中有更加简洁的方法。
在 Golang 中,标准的 Goroutine Pool 并发由以下几项组成:
- WaitGroup,负责对 goroutine pool 进行管理(类似于父进程对子进程进行回收的概念)
- Channel, Goroutine workers 通过 channel 读取要处理的数据
- close(channel), 一旦 channel 已经关闭了,那么 Goroutine workers 对channel 的 for loop 也会终止
正是因为 Golang 提供了以上 3 项语言特性,使得用 goroutine pool 进行并发处理的代码变得十分简单,以下是一个模板。
package main
import (
_ "expvar"
"fmt"
"math/rand"
"sync"
"time"
)
const maxWorkers = 10
type job struct {
name string
duration time.Duration
}
func doWork(id int, j job) {
fmt.Printf("worker%d: started %s, working for %fs\n", id, j.name, j.duration.Seconds())
time.Sleep(j.duration)
fmt.Printf("worker%d: completed %s!\n", id, j.name)
}
func main() {
// channel for jobs
jobs := make(chan job)
// start workers
wg := &sync.WaitGroup{}
wg.Add(maxWorkers)
for i := 1; i <= maxWorkers; i++ {
go func(i int) {
defer wg.Done()
for j := range jobs {
doWork(i, j)
}
}(i)
}
// add jobs
for i := 0; i < 100; i++ {
name := fmt.Sprintf("job-%d", i)
duration := time.Duration(rand.Intn(1000)) * time.Millisecond
fmt.Printf("adding: %s %s\n", name, duration)
jobs <- job{name, duration}
}
close(jobs)
// wait for workers to complete
wg.Wait()
}